本記事では「DioDocs(ディオドック)」を使用して、PDFで保存されている市外局番のデータを読み込み、CSVで出力する方法について説明します。PDFのままではデータとして利用することはなかなか手間がかかるかと思いますが、データをCSVに落とし込むことで他のサービスやアプリケーションで利用しやすくなります。
市外局番
市外局番は総務省のサイトからダウンロードできます。
市外局番は以下のようなPDFおよびWordで提供されています。これらに含まれるデータを取得してCSVに出力する方法を紹介します。
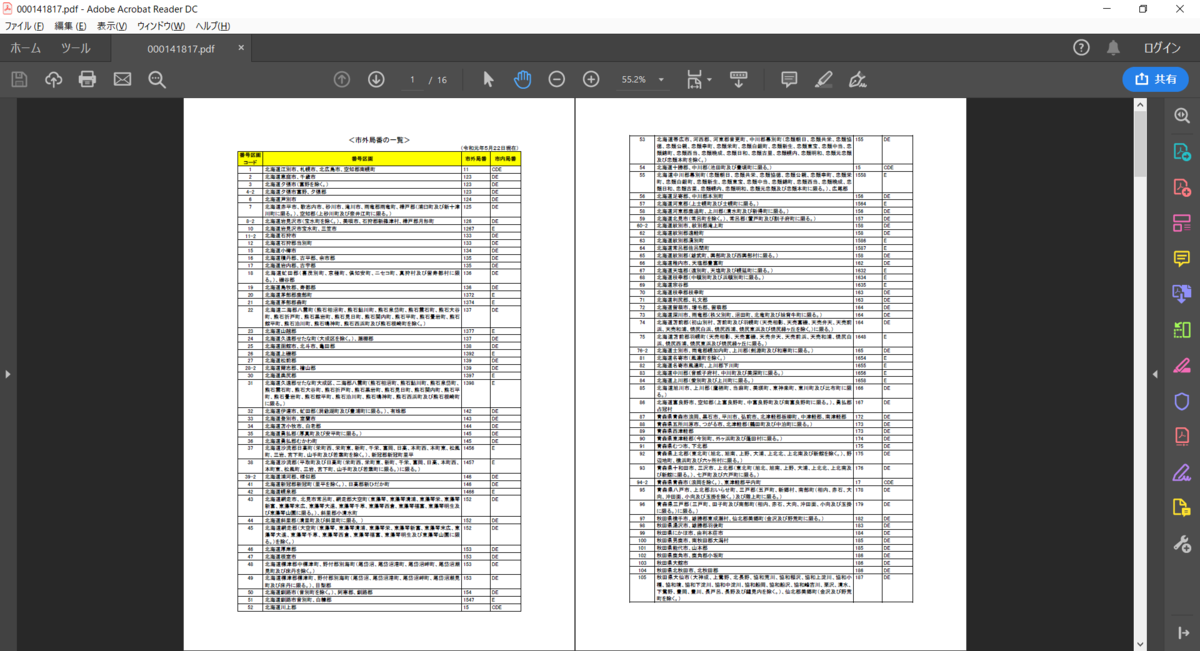
ここで使えるのが「DioDocs for PDF」です。
DioDocs for PDF
DioDocs for PDFのGrapeCity.Documents.Pdf.PageクラスにはGetTextメソッドがあり、これを使用することでGcPdfDocumentオブジェクトに読み込んだPDFの各ページのテキストを抽出することができます。この動作は以下のデモで確認いただけます。
さらにGrapeCity.Documents.Pdf.GcPdfDocumentクラスにあるGetTextメソッドを使用すれば、GcPdfDocumentオブジェクトに読み込んだPDFのすべてのテキストを抽出することができます。
今回はこの機能を使用してPDFからデータを抽出し、CSVで出力します。
処理の流れ
DioDocsのGrapeCity.Documents.Pdf.GcPdfDocumentクラスのLoadメソッドで対象となるPDFを読み込んで、GetTextメソッドでPDFの全テキストを取得しています。あとはデータを整えてCSVに出力する処理になっています。
実際のコード
using GrapeCity.Documents.Pdf; using System; using System.IO; using System.Text; namespace DDPdfGetText { class Program { static void Main(string[] args) { // ライセンスを設定します GcPdfDocument.SetLicenseKey("トライアル版もしくは製品版のライセンスキー"); // PDFドキュメントを作成します GcPdfDocument pdf = new GcPdfDocument(null); // 出力先のCSVが既に存在する場合は削除します if (File.Exists("shigai_list.csv")) File.Delete("shigai_list.csv"); // データを取得するPDFと出力先のCSVを開きます using (FileStream _pdf = new FileStream("000141817.pdf", FileMode.Open)) using (FileStream _csv = new FileStream("shigai_list.csv", FileMode.Append)) { // PDFを読み込みます pdf.Load(_pdf); // 取得したテキストを格納する文字列 string list = ""; // 全ページのテキストを取得します。表のセルごとのテキストが半角スペース2個で // 区切られて取得されるので半角スペース2個をカンマに変換します list = pdf.GetText().Replace(" ", ","); // 表のタイトル「<市外局番の一覧>」等は必要ないのでデータ部分だけを抽出します list = list.Substring(list.IndexOf("1,")); // 取得したテキストを「LF(\n)」で1行ごとに分割します string[] lines = list.Split(new char[] { '\n' }, StringSplitOptions.RemoveEmptyEntries); // 分割したデータを末尾から1行ずつチェックして修正します for (int i = lines.Length - 1; i > -1; i--) { // チェックするデータを取得します string line = lines[i]; int x = 0; // 最初の1文字目が数字かどうかをチェックします if (int.TryParse(line.Substring(0, 1), out x)) { // カンマで区切って1レコード分のデータが揃っているか調べます string[] param = line.Split(new char[] { ',' }); // 項目が4つ未満の場合(1レコード分のデータが不足している場合) if (param.Length < 4) { // 一つ上の行のデータを取得して末尾の「CR(\r)」を除去します string line2 = lines[i - 1].TrimEnd(new char[] { '\r' }); if (param.Length == 2) { // 項目が2つの場合(表の3列目と4列目の場合)、 // 上の行とカンマで連結します。(例)「823,DE 」 lines[i - 1] = line2.TrimEnd() + "," + line; } else { // 上の行と連結します(表の2列目~4列目の場合) // (例)「578の番号区画を含む。),92,CDE 」 lines[i - 1] = line2.TrimEnd() + line; } // 不要なデータは消去します lines[i] = ""; } else { // 1レコード分のデータが揃っている場合 // 不要なスペースを除去して「LF(\n)」を追加します lines[i] = lines[i].Replace(" ", ""); lines[i] = lines[i] + '\n'; } } else // 1文字目が数字以外の場合は上の行のデータと連結します { // 一つ上の行のデータを取得して末尾の「CR(\r)」を除去します string line2 = lines[i - 1].TrimEnd(new char[] { '\r' }); // 一つ上の行の1文字目が数字かどうかをチェックします if (int.TryParse(line2.Substring(0, 1), out x)) { if (line2.IndexOf(',') < 0) { // 一つ上の行が数字だけの場合(表の1列目だけの場合)、 // トリムしてカンマを追加します。(例)「531 」 line2 = line2.TrimEnd() + ","; } } // 上の行と連結して1レコードにします lines[i - 1] = line2.TrimEnd() + line; // 不要なデータは消去します lines[i] = ""; } } // 修正したデータを1つにまとめます StringBuilder sb = new StringBuilder(); for (int i = 0; i < lines.Length; i++) { // 空以外のデータを取得します if (lines[i].Length > 0) sb.Append(lines[i]); } // CSVに保存します(Encoding.Defaultは日本語版Windowsでは「Shift_jis」) Byte[] data = Encoding.Default.GetBytes(sb.ToString()); _csv.Write(data, 0, data.Length); } } } }
今回はライセンスの設定が必要です
DioDocsはNuGetからインストールしてライセンスを設定していなくても動作を確認できるのですが、ライセンスを設定していない場合はPDFの読み込みが「5ページ」までに制限されており、出力されるCSVも5ページまでとなります。
元のPDFは16ページあるので、すべてをCSVに出力して確認する場合はトライアル版のライセンスキーを設定する必要があります。
確認してみる
こちらのデモで動作を確認できます。
デモを実行してCSVに出力された結果を確認してみます。
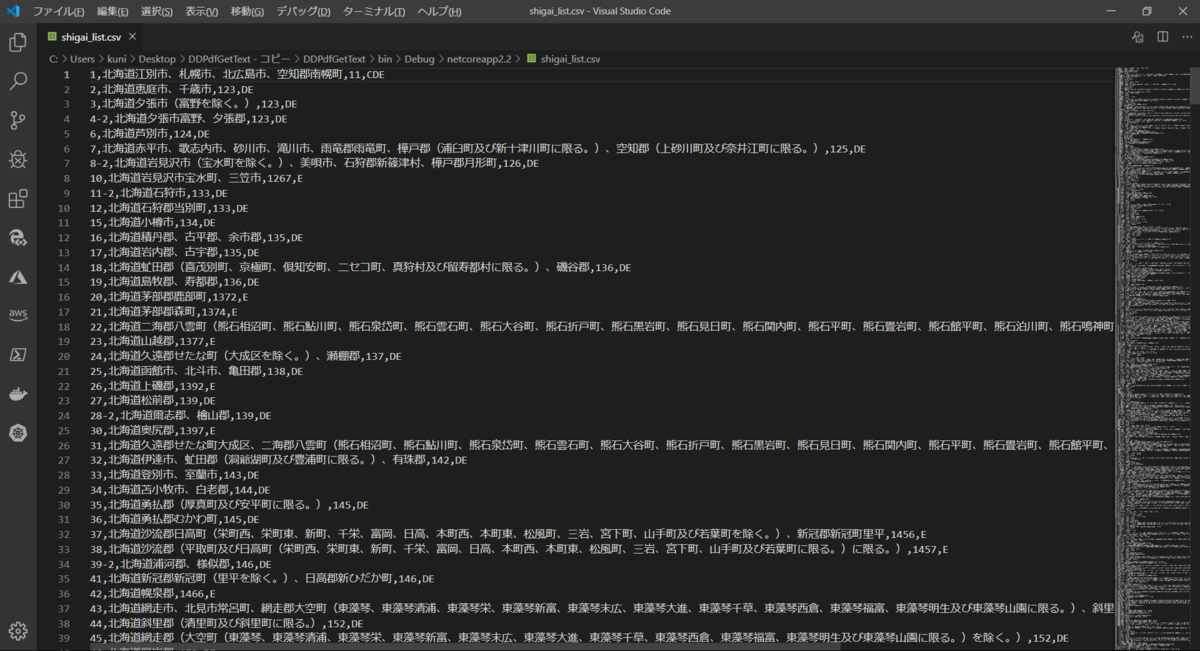
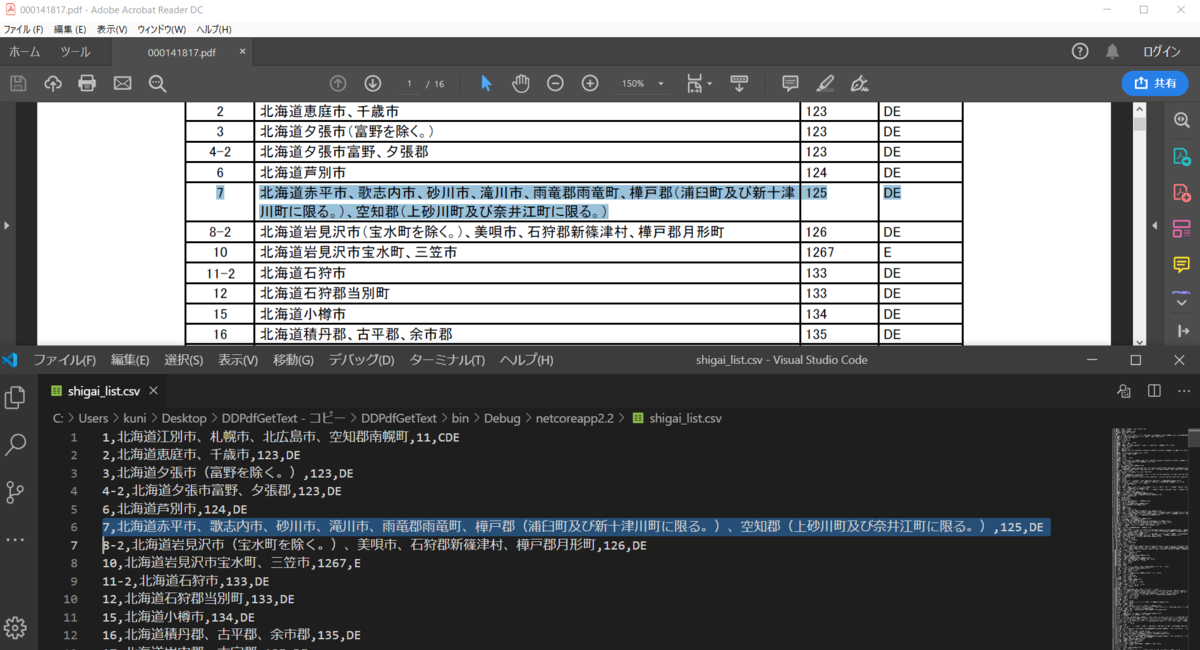
複数行で構成されているデータ部分を参照してみると、正しく一行に整形されていることが確認できます。
キャッシュレス還元対象店一覧もできるハズ…?
今回と同じくPDFからデータを抽出し、CSVで出力するケースですね。ただしデータのボリュームが桁違いにスゴイ…。
こちらもDioDocsで今後取り組んでみたいと思います。乞うご期待!!
弊社Webサイトでは、製品の機能を気軽に試せるデモアプリケーションやトライアル版も公開していますので、こちらもご確認いただければと思います。
また、ご導入前の製品に関するご相談やご導入後の各種サービスに関するご質問など、お気軽にお問合せください。